우리가 매일 사용하는 AI는 어떻게 똑똑해지는 걸까요? 단순한 데이터 처리부터, 인간의 피드백을 반영하는 최신 튜닝 기법(LoRA, RLHF)까지! 현존하는 최고의 인공지능 학습 방법과 모델의 작동 원리를 깊이 있게 해부합니다. 이 가이드를 통해 AI 학습의 본질을 이해하고, 나만의 AI 프로젝트를 최적화할 인사이트를 얻어보세요.
솔직히 말해서, 저는 인공지능 분야에 몸담고 있지만 AI가 매번 새로운 것을 학습하고 결과를 만들어내는 과정을 볼 때마다 놀라고 한편으로는 무섭기 까지도 합니다. 마치 어린아이가 세상을 배우듯, A.I도 끊임없이 데이터를 통해 세상의 모든 내용을 '경험'하며 진화하고 있습니다. 그런데 그 '경험'이라는 게 뭘까요? 단순한 데이터 주입? 당연히 그렇지 않습니다.
AI 학습은 학습 모델(뇌), 학습 방법(교육법), 그리고 최적화(효율적인 공부 습관)라는 세 가지 축으로 이루어져 있어요. 이 글에서 저는 이 세 가지 핵심 요소를 최신 트렌드를 반영하여 쉽고 명쾌하게 설명해 드릴 거예요.
AI의 심장이 뛰는 방식을 함께 들여다 볼까요?
AI의 뇌, 학습 모델의 진화: 신경망 아키텍처 🧠
인공지능의 지능 수준은 결국 어떤 '뇌'를 가지고 있느냐에 달려있어요. 과거의 단순한 인공 신경망(ANN)부터 시작해, AI 모델 아키텍처는 정말 눈부시게 발전했죠. 요즘 AI를 이끄는 두 거대한 축이 있습니다.
1. 언어/순차 데이터의 제왕: 트랜스포머 (Transformer) 📝
2017년에 등장한 트랜스포머는 AI 역사의 한 획을 그었어요. 이 모델의 핵심은 '어텐션(Attention)' 메커니즘인데, 이게 뭐냐면요. 제가 어떤 문장을 읽을 때, "어제 먹은 밥이 너무 맛있더라"라고 하면, 저는 '밥'이라는 단어를 볼 때 '어제'나 '먹은'에 더 집중하잖아요? 트랜스포머는 데이터의 모든 요소 중에서 가장 중요한 부분에 집중(Attention)하는 능력을 인공적으로 구현한 거예요. 이게 바로 GPT, BERT 같은 대규모 언어 모델(LLM)이 탄생할 수 있었던 기반이죠.
2. 창조의 엔진: 확산 모델 (Diffusion Model) 🎨
요즘 이미지를 뚝딱 만들어내는 Midjourney나 DALL-E를 보면 신기하잖아요? 이 뒤에는 확산 모델이 있습니다. 이건 마치 그림을 그릴 때, 깨끗한 캔버스에 노이즈(잡음)를 잔뜩 넣은 다음, 그걸 조금씩 걷어내면서(De-noising) 원하는 이미지를 복원하는 방식과 같아요. 이 방식은 기존 GAN(적대적 생성 신경망)보다 훨씬 안정적이고 고품질의 결과물을 만들어내서, 요즘 생성형 AI의 대세로 자리 잡았습니다.

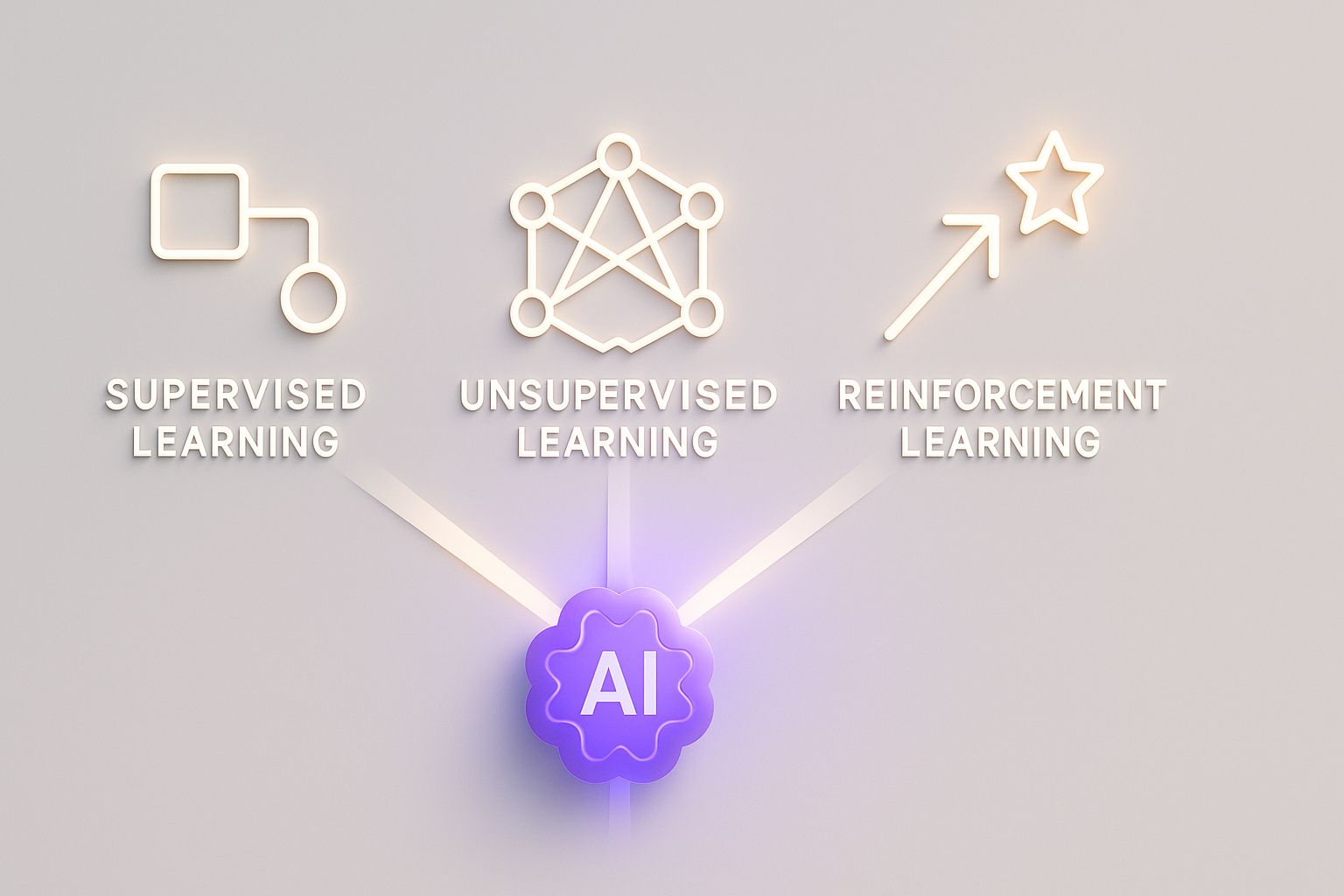
AI를 똑똑하게 만드는 3가지 핵심 학습법 💡
모델이라는 '뇌'가 있다면, 이 뇌를 교육하는 방법이 필요하겠죠? AI 학습은 크게 세 가지 패러다임으로 나뉩니다.
데이터와 정답(레이블)을 쌍으로 제공하여 모델이 오차를 줄이도록 훈련합니다. 마치 시험 문제와 정답을 함께 주고 공부시키는 것과 같아요. 분류(Classification)나 회귀(Regression) 문제에 주로 사용됩니다.
정답지 없이 데이터만 제공하여, 모델이 스스로 데이터 내부의 숨겨진 구조나 패턴을 파악하게 합니다. 군집화(Clustering), 차원 축소(Dimensionality Reduction) 등이 여기에 속하며, 최근에는 자체 지도 학습(Self-Supervised Learning, SSL)이 대규모 모델의 사전 학습(Pre-training)에 혁명을 가져왔습니다.
AI 에이전트가 특정 환경(Environment)에서 행동(Action)을 취하고, 그 결과에 따라 보상(Reward)을 받거나 벌칙(Penalty)을 받으며 최적의 전략을 스스로 찾아 나섭니다. 마치 강아지에게 칭찬(보상)과 꾸짖음(벌칙)으로 훈련하는 것과 유사하죠. 알파고(AlphaGo)가 대표적인 성공 사례입니다.
개인적으로 비지도 학습의 진화가 정말 놀라워요. 예전에는 레이블링(정답 달기) 비용 때문에 프로젝트의 80%가 지연되곤 했는데, 이제는 SSL 덕분에 대규모 데이터셋을 활용해 먼저 '세상의 이치'를 깨달은 AI를 만든 다음, 아주 적은 양의 레이블링 데이터로 특정 작업을 튜닝하는 시대가 열렸거든요.
성능을 좌우하는 2024년 최신 튜닝 기법 (학습 최적화 가이드)
좋은 모델과 학습 방법을 골랐다면, 이제 '어떻게 가장 효율적으로 훈련시킬지'가 중요합니다. 여기서 최적화(Optimization)와 튜닝(Tuning)이 들어와요.
핵심 1: 학습 속도를 조절하는 옵티마이저 (Optimizer)
옵티마이저는 모델이 오차(Loss)를 줄이기 위해 가중치(Weight)를 어떻게 업데이트할지 결정하는 알고리즘이에요. 가장 많이 쓰이는 옵티마이저는 Adam과 SGD(Stochastic Gradient Descent)의 변형입니다.
옵티마이저의 역할 📝
- Adam: 모멘텀과 적응형 학습률을 결합하여 빠르고 안정적인 수렴을 돕습니다. 초기 세팅에 가장 많이 사용됩니다.
- SGD/Momentum: 느리지만 때로는 더 나은 최종 일반화 성능을 제공합니다.
핵심 2: 대규모 모델 시대를 연 미세 튜닝 (Fine-Tuning) 혁신
수십억 개의 파라미터를 가진 거대 AI 모델을 매번 처음부터 학습시키는 건 시간과 비용 낭비잖아요. 그래서 요즘은 '전이 학습(Transfer Learning)'과 미세 튜닝이 필수예요. 특히 2024년에는 이 미세 튜닝의 효율을 극대화하는 두 가지 기법이 주목받고 있습니다.
- LoRA (Low-Rank Adaptation) 📉:모델의 전체 파라미터를 학습시키는 대신, 파라미터의 작은 부분집합만 훈련시키는 기법입니다. 기존 모델의 성능은 유지하면서도, 튜닝에 필요한 메모리와 시간을 획기적으로 줄여줘요. 이건 마치 거대한 교과서 전체를 다시 쓰는 게 아니라, 핵심 요약 노트만 업데이트하는 것과 같죠.
- RLHF (Reinforcement Learning from Human Feedback) 🙋♀️:사람의 피드백을 보상 신호로 사용하여 AI를 강화 학습시키는 방법입니다. GPT-4와 같은 최신 LLM들은 이 RLHF를 통해 인간의 가치관과 선호도에 맞춰 정렬(Alignment)됩니다. 이 과정에서 AI는 단순히 정확한 답변이 아니라, 인간이 보기에 '가장 좋은' 답변을 학습하게 되죠.
AI 학습에서 가장 경계해야 할 것은 '과적합'입니다. 이건 모델이 훈련 데이터는 완벽하게 외웠지만, 새로운 데이터에는 젬병인 상태를 말해요. 마치 시험 범위를 달달 외워서 만점을 받았지만, 응용 문제는 전혀 못 푸는 학생과 같죠. 조기 종료(Early Stopping)나 드롭아웃(Dropout) 같은 정규화 기법으로 이를 방지해야 합니다.
학습 방법별 특징 한눈에 비교
| 구분 | 데이터 유형 | 주요 목표 | 대표 활용 예시 |
|---|---|---|---|
| 지도 학습 | 입력 & 정답(레이블) | 정확한 예측/분류 | 스팸 필터링, 이미지 인식 |
| 비지도 학습 | 레이블 없는 데이터 | 패턴 및 구조 발견 | 고객 군집화, 대규모 사전 학습 |
| 강화 학습 | 환경, 행동, 보상 | 최적의 순차적 결정 | 자율 주행, 게임 전략 |
AI 학습, 이것만 기억하세요! (핵심 공식) ✨
AI 학습을 위한 3가지 황금률
(여기서 $\eta$는 학습률(Learning Rate), $\nabla L(W)$는 손실 함수의 기울기(Gradient)입니다. 옵티마이저는 이 과정을 가장 효율적으로 수행하죠!)
자주 묻는 질문 ❓
지금까지 AI가 어떻게 학습하는지, 그리고 어떤 최신 기술로 효율을 높이고 있는지 함께 살펴봤는데요. 복잡하게만 느껴졌던 AI 학습의 과정이 조금은 명쾌하게 다가오셨나요? 저는 이 모든 과정이 마치 AI라는 거대한 예술 작품을 다듬어 가는 과정 같다고 생각합니다. 여러분이 AI에 대해 더 깊이 이해하고, 궁극적으로는 이 기술을 활용해 멋진 결과물을 만들어내는 데 이 글이 작은 씨앗이 되기를 바랍니다.

※ 유의사항 ※
1). 본 아티클은 제작자의 창작물이며, 지적 재산권에 의해 보호됩니다. 저작자의 허락 없이 다른 저작물에 도용하거나, 저작자 허락 없이 상업적 목적에 이용하거나 유출하는 경우, 민형사상의 불이익과 처벌을 받게 되니 주의하시기 바랍니다.
2). 본 컨텐츠의 원문은 저작자가 직접 자료조사를 통해 작성했으며, 그 다음에 블로그용 글을 다듬는 작업만을 Google Gemini로 작업한 글입니다.
3). 본 컨텐츠에 사용된 이미지는 GPT Image에서 주제를 입력한 Prompt로 생성한 이미지를 사용하였습니다.
'꿈을 그리는 A.I' 카테고리의 다른 글
| 폐쇄환경에서 생성형 AI를 설치, 활용하는 방법 (0) | 2026.03.02 |
|---|---|
| CLI (Claude, Gemini)의 하이브리드 메타추론 적용방법 (1) | 2025.10.16 |
| We are...(Part 1) (0) | 2025.10.05 |
| AI, 이제 스스로 배운다: Reflexion Prompting의 원리와 활용 (3) | 2025.09.25 |
| 양자 컴퓨팅과 AI의 결합, AI와 양자 물리학이 만나 만들어지는 다음 세계 (3) | 2025.09.24 |